I’m Getting Bored Of The Double Parabola
For test purposes the double parabola was a really great function to minimize: easy to understand, easy to visualize and easy to double check. But it’s also kind of boring and doesn’t really test the strengths and weaknesses of our swarm intelligence.
So I’ve come up with three new functions to help break the parabolic monotony we’ve gotten ourselves stuck in.
Finding A Minimum In A World With No Minimums
Optimizers are based around the idea that problems actually have optimum answers, that some solutions to a problem are better than others. But what if this wasn’t the case? What if every possible answer was equally optimal? What if every answer is exactly the same?
(defun flat-function (x y) "Always return 7, because it's a nice number" 7)
This function technically has a minimum of 7, but that minimum exists everywhere. There is no wrong answer. So let’s see how the swam optimizer handles this.
A swarm optimizing a function with no optimum… whatever that means
Basically the swarm just latched onto the first guess it made, which obviously returned 7. Since no other guess ever returned anything smaller than 7 the swam quickly gravitated to that first, random guess.
You can see here that I ran the optimizer again and it got a different but equally correct answer. So the swarm optimizer can handle flat functions just fine by generating a random answer and sticking with it.
Same size swarm optimizing the same flat function but getting a different random answer
That was actually more boring than the parabola. Let’s move onto something else.
There’s A Hole In Your Problem Space
The parabola is a nice smooth function where values change gradually and it is easy to just “roll down the hill” to find the minimum. We’re going to mix that up now by creating a function that is mostly a smooth parabola, but also has a sudden big hole somewhere around (3,3). The true minimum will be inside that hole.
(defun double-parabola-with-hole ( x y)
(if (and (>= x 3) (<= x 3.1) (>= y 3) (<= y 3.1))
(- (+ (* x x) (* y y)) 100)
(+ (* x x) (* y y))))
This is a pretty simple step function. If X and Y are both inside the tiny window of 3 to 3.1 then we calculate the normal parabola and then subtract 100. Otherwise we just calculate the normal parabola. This results in a problem space that basically looks like a giant bowl with a really deep but tiny square hole cut into one of the sides.
The test here is to see if the swarm can find that hole or if it just rolls down the hill and gets stuck thinking (0, 0) is the the true minimum instead of the local minimum it really is.
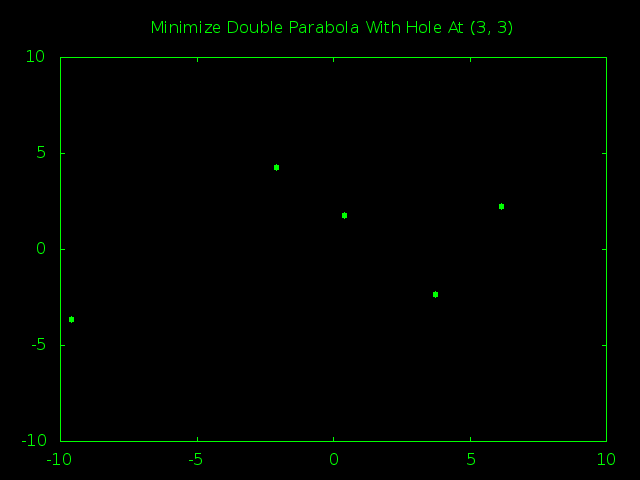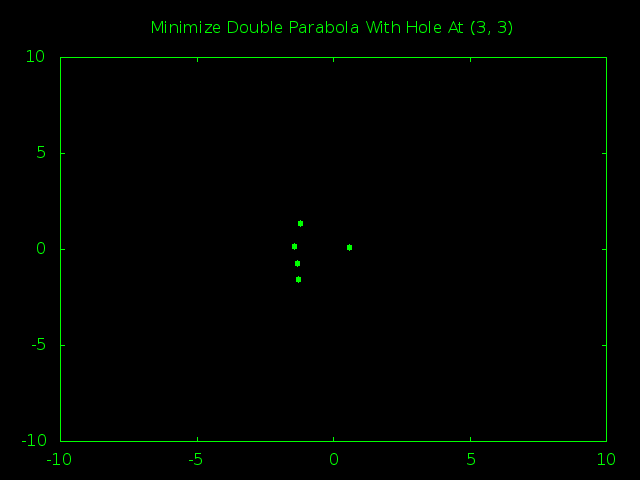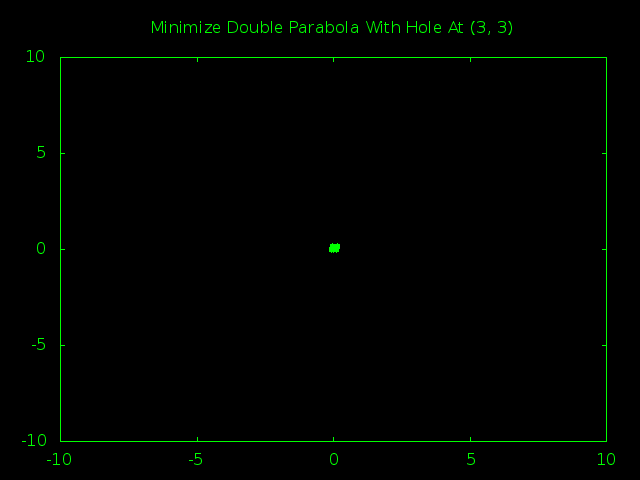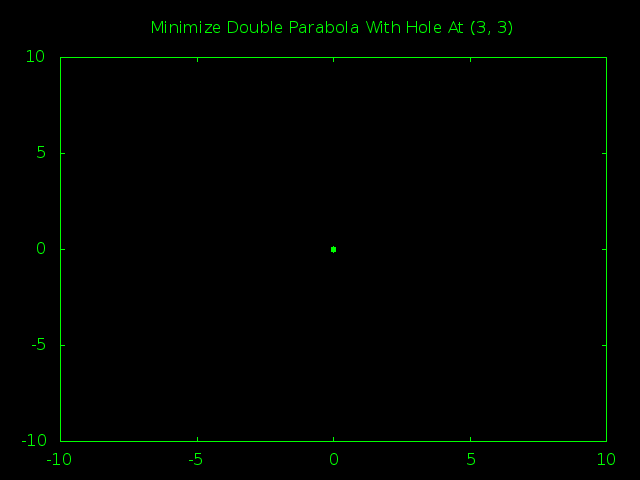
That’s not the minimum!
A quick look at this animation shows that my normal 5 particle swarm running for 75 iterations just can’t find the tiny true minimum hiding at (3, 3).
Increasing the iteration count isn’t going to help; the swarm will just spend even more time zooming ever closer to the local minimum at (0, 0).
But if more time won’t help, what about more particles? The more particles we have zooming around the bigger the chances there are that one of them will eventually stumble across our hole and alert the swarm that they really need to be looking in the (3, 3) region.
So I started kicking up the size of the swarm. 50 particles was no good. 100 particles failed too. 200, 300, 400, 500… nothing. They all just gravitate to the origin.
Time for the big guns. A 1,000 particle swarm managed to find the true minimum hole a little less than half the time. A 2,000 particle swarm had closer to an 80% success rate. Here is a snapshot of the 2,000 particle swarm in action.
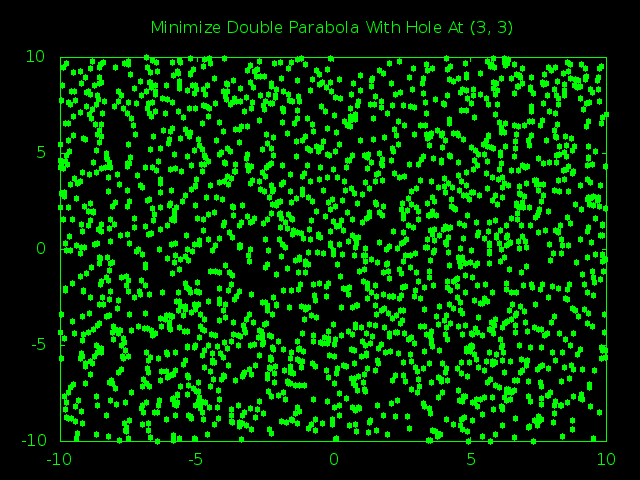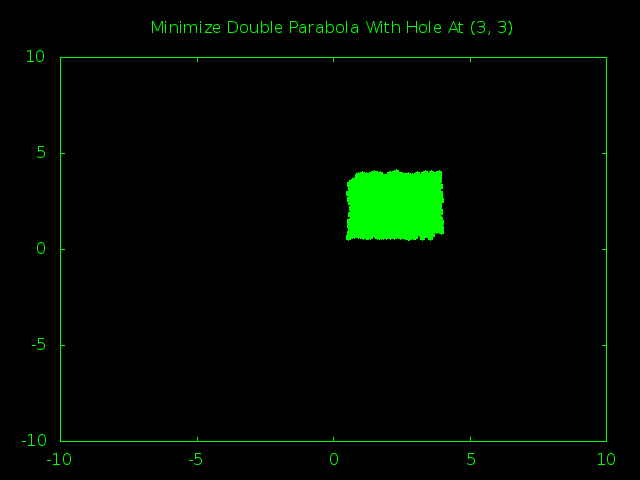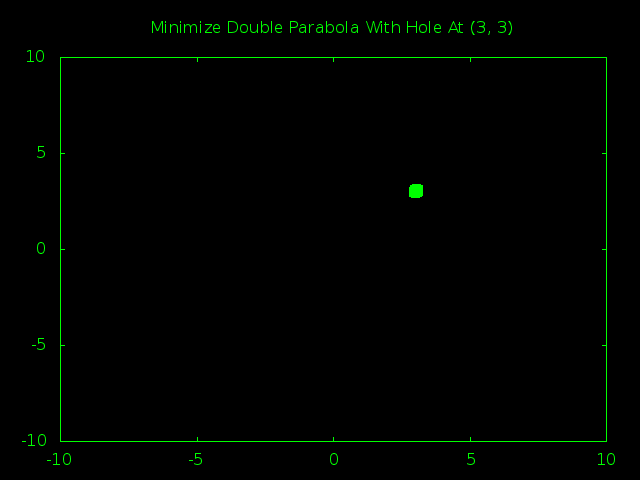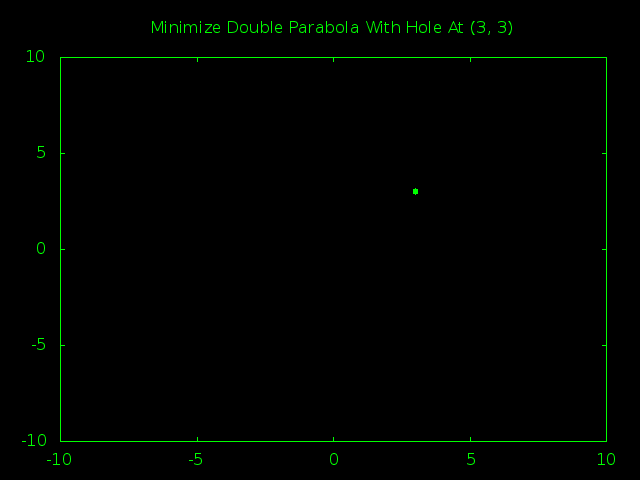
First off, isn’t it kind of cool how the way we define our borders wound up squashing the swarm into a big rectangle shape instead of the generic blob we would expect?
Second, you can actually see that at the start the swarm still thought that (0, 0) was the smartest place to look for a minimum. It was only after the first few steps that one of the particles got lucky and noticed that there were even smaller values around (3, 3) and managed the drag the entire swarm in the right direction.
I suspect that if our hole was even farther away from the obvious fake minimum then it would take even more particles to reliably find it. For example, if the hole was at (9, 9) you would probably needs tends of thousands of particles just to make sure that even after most of the particles headed straight for the origin there were still a few thousand slowly circling the edge.
Exercise for the reader: Create a double-parabola with a 0.1 x 0.1 hole at (9, 9). Find out how big the swarm has to be before it can find the right answer 90% of the time.
Bonus Exercise for the reader: Create a series of double parabolas with 0.1 x 0.1 holes at (1, 1), (2, 2), (3, 3), (4, 4) and so on until (9, 9). Record how big the swarm has to be in order to achieve 90% success rate for each hole. Is there a pattern between how far away the hole is from the natural parabola minimum and how large the swarm has to be to find it?
How To Get Better At Finding Holes
This whole “find the tiny square where the optimal value is hiding” shows off the big weakness of our overly simplistic swarm intelligence. Because particles obsess only about the global best answer so far they do not spend a lot of time exploring their own corner of problem space before shooting off and clumping up with the other particles. Unless we use a huge swarm we are at high risk of getting stuck on local optimums.
There are a couple ways an ambitious reader could fix this problem. One would be to upgrade the swarm so that particles keep a memory of their own best solution so far in addition to the global best solution and then have them choose their next guess based off of both of those numbers. This will slow down how fast the swarm clumps together and give you a better look at all of problem space.
Of course, this isn’t a miracle solution. It really only works in scenarios where you have multiple, obvious trends. Imagine a plane filled with lots of little valleys, some shallower than others. Local best answers allow particles to roll towards the bottom of their own valley before getting too excited about the global smallest answer so far. This way a particle that randomly starts out at the bottom of a shallow valley can’t dominate all the other particles that randomly started near the top of much deeper, and better, valleys.
However, think back to our parabola with a whole. All the particles are in the same “bowl”. Their local bests will lead them to roll down to the center, just like the global best did. So in this particular case the local best doesn’t really help us.
So another option might be to add some extra chaos into the system by creating a new type of “scout” particle that doesn’t care as much about global or local bests as a normal particle would. Instead it randomly changes its velocity, breaking away from the central swarm in order to explore areas that the rest of the swarm ignored.
To be honest it’s a long shot that one of these scout particles is going to find something that the rest of the swarm somehow didn’t on their way to clumping together… but a small chance is better than no chance. Even better, since scout particles don’t settle down like normal particles their chance of finding a new answer just keeps going up the longer the swarm is alive.
So if you plan on having a long running swarm, maybe on that runs forever and reports its current best every hour, then you really should probably code up some scout particles. This is especially important if you are working with a problem space that changes. It would be sad if a new optimum suddenly appeared in a corner and you never found out because your particles had already clumped together somewhere else and were no longer active enough to notice the change.
A Bumpy Problem Space
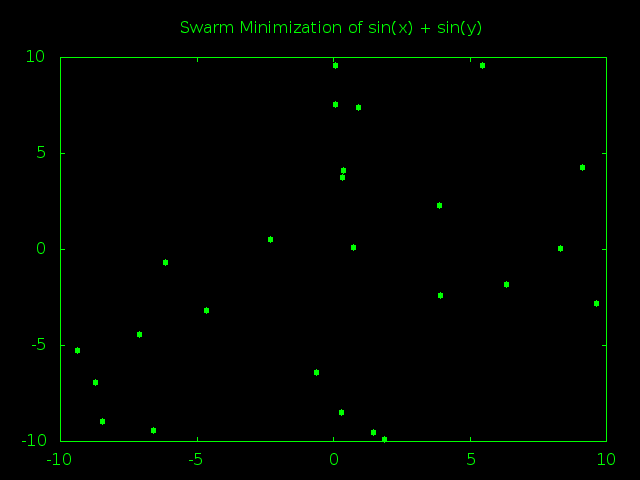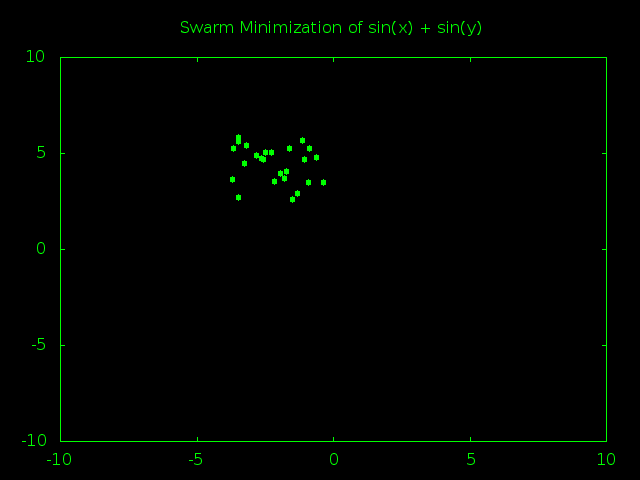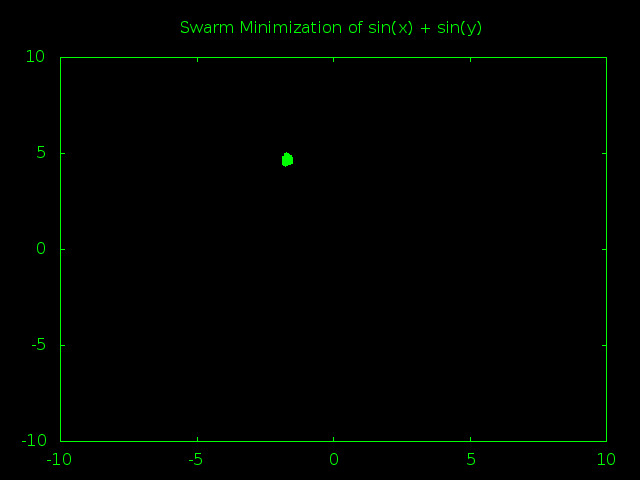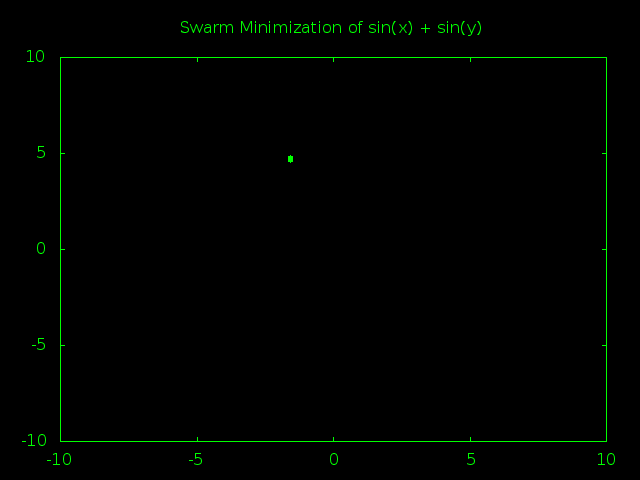
So we’ve already covered a problem with no optimums* and a problem with one very hard to find optimum. Now let’s try a problem with a couple dozen optimums spread evenly throughout problem space.
(defun double-sine-wave (x y) (+ (sin x) (sin y)))
I’m sure you’ve seen a sine wave. This is two sine waves put together in what would look like a giant field filled with dozens of hills and valleys, all exactly the same size.
Honestly this will be a boring experiment. If we had local minimum code then we could probably see a bunch of particles rolling around their nearest valley before finally all grouping up at some randomly selected global best valley… but that’s not what we have. All we have is a global minimum so odds are the particles will bounce around a bit and then all clump up at one spot pretty fast.
[5]> (defparameter *swarm-size* 25)
*SWARM-SIZE*
[6]> (defparameter *swarm-iterations* 75)
*SWARM-ITERATIONS*
[7]> (defparameter *swarm-output* (swarm-minimize-2d #’double-sine-wave ‘(-10 10) ‘(-10 10)))
*SWARM-OUTPUT*
[8]> (first *swarm-output* )
(-1.570653 4.7121253)
[9]> (double-sine-wave -1.57 4.71)
-1.9999969
OK, -2 is the smallest value you can get by adding together two sine functions so good job there. Now it’s time to animate the history:
The minimum is over here… or is it over here? Wait, definitely here!
Meh, I guess this is *kind-of* interesting. You can see how the first global minimum was inside of one valley, then a particle bumped into another valley and the whole swarm started moving that way before bumping into a third valley and finally settling there. It’s at least more interesting than the standard double parabola where everything heads for the center almost from the very start.
Time To Transcend This Plane Of Existence
I think I’ve covered everything I wanted to for two dimensional swarms, so next time around we’ll be working on creating a more general swarm that can handle higher dimension equations. The hardest part is probably going to be coming up with some easy to understand test functions.
Does anybody have any idea what a nine dimensional octuple-parabola would look like?
* Or is that an infinite number of optimums? Consider it the math version of the “is the glass half empty or half full” question.