An Extremely Easy Sample Optimization
Now that we have a swarm it’s time to teach it how to go out and conquer the stars… I mean teach it how to properly optimize a function. And for that we’re going to need a test function we can practice with.
We want our first testing function to be simple enough that we humans can double check the computer’s work without having to waste thirty minutes pecking numbers into our graphing calculators*. Later on we can come up with some complex tests to really give the swarm a run for its money but for now we want easy.
And what’s easier than a parabola? You just can’t beat good old x^2 when it comes to predictable equations with an obvious minimum. Everyone can see that the obvious minimum of x^2 is when x equals 0, right?
But this is a two dimensional swarm, and parabolas are only single variable problems. We want a two dimensional problem. So behold! The double parabola: x^2 + y^2
The optimized minimum of this two variable problem is just as obvious as the one variable version. When both x and y are 0 the final answer is also zero.
In Lisp terms our double parabola looks like this
(defun double-parabola (x y)
(+ (* x x) (* y y)))
If we feed this function into our particle swarm it should ideally spit back an answer very close to (0, 0). And now that we know what we’re looking for we can start programming some swarm logic.
A Reminder Of How This Whole Thing Works
You’re probably getting bored of me explaining the basics of swarm intelligence over and over again, but if years of Sesame Street have taught me anything it’s that repetition is an important part of learning. So here we go, one last time, to make sure you’re 100% ready to actually program this thing.
Our goal is to take an equation with two variables and try to find the input that will give us the most optimal answer, defined here as the smallest answer possible (a minimum). So if we find two possible answers of 10 and 5 we consider the smaller number, 5, to be more optimal.
In order to try and find the most optimal, minimal answer for the entire equation we create a bunch of particles that all have a position and a velocity. The position represents a possible set of input values to the equation. The velocity represents how much we want to increase or decrease those inputs before making our next guess.
We run the swarm by looping through all the particles and feeding their position/input into the function we are trying to optimize. We keep track of what input has produced the most optimal guess so far. After each particle has made it’s guess we update their velocity to point a little bit more towards our best answer. Then we move all the particles based off of their velocity and repeat the process.
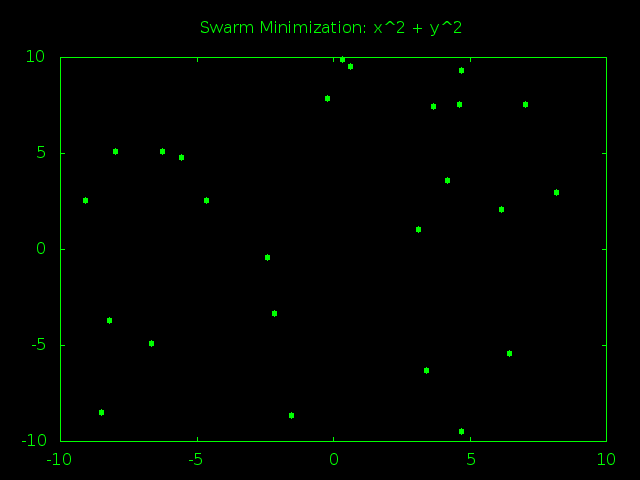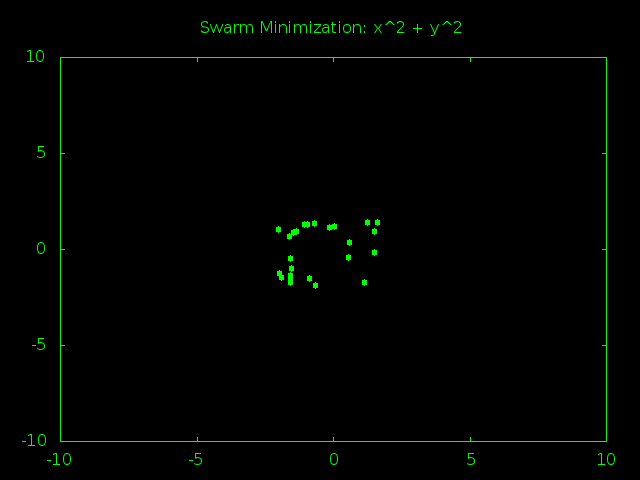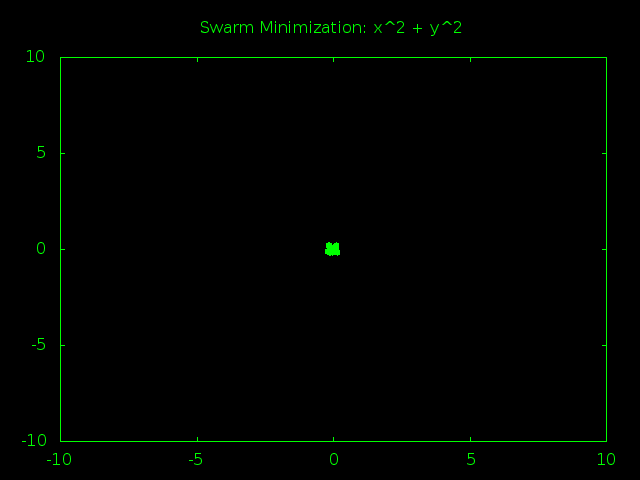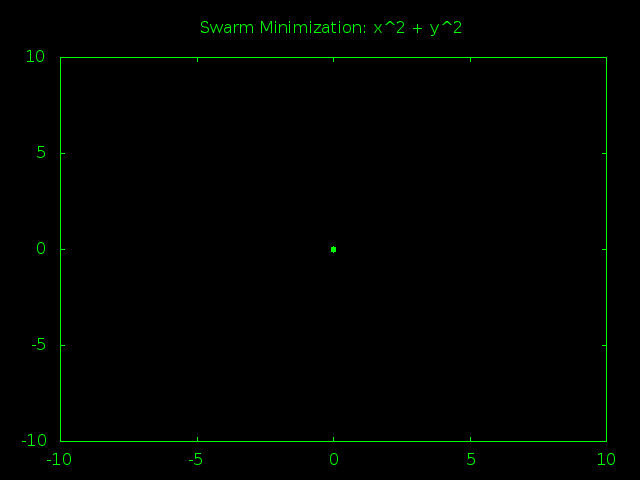
What this should do is create a bunch of random particles that make tons of random guesses. As time goes on the particles will start agreeing on a best answer and their velocity will begin to point towards it. This will cause the particles to get closer to each other so they can focus their guessing power around good answers. Eventually the particles will all be clumped together and stop finding new, better answers. At that point we grab the best answer so far and call it our best educated guess on what the true minimum must be.
Starting Small
This is a pretty complex problem, or at least pretty complex for a single blog post. So instead of jumping straight in and trying to write an algorithm for updating an entire swarm let’s take it easy and write an algorithm for updating a single particle. We’ll need that function for the bigger swarm algorithm anyways.
Updating a particle is a five step process:
- Add the particle’s current position to its history.
- Use the particle’s current position to generate an answer to the function we want to optimize.
- Compare that answer to the current swarm best answer. If it is better, update the swarm best.
- Update the particle’s velocity to point slightly more towards the swarm best.
- Update the particle’s position based off of it’s velocity, but make sure it stays in the bounds of the problem.
In order to pull all that off we’re going to need the following pieces of information:
- The particle we are updating
- The swarm we are updating
- The function we are optimizing
- The boundaries of the problem.
Which leads us to this:
(defun update-swarm-particle-2d (particle swarm fn x-bounds y-bounds)
;Code goes here)
Turning A Function Variable Back Into A Function
One more bit of Lisp you’re going to need to know in order to construct this algorithm. You might remember that Lisp lets you create a function reference really easy with the #’function-name syntax, which will make it easy for us to toss our double-parabola around as #’double-parabola. But putting a function into a variable is only half the battle. We also need to get it back out.
This is as easy as using funcal. The first argument is a variable holding a function reference and then the rest of the arguments become data for that function. Ex:
[4]> (defparameter *test-fn* #’double-parabola)
*TEST-FN*
[5]> (funcall *test-fn* 2 5)
29
Would You Like To Save Your Data?
With that out of the way we can start going through the five steps of the algorithm. The first is to add the particle’s current position to its history, which is easy enough to do with the append function. This may not be the most efficient way to build the history data structure, but until we have real data on whether the algorithm is fast or slow there’s no point obsessing about this.
The trick to watch out for here is that append expects two lists. It then takes every item in the second list and puts it into a copy of the first list. So if we want to add a two item list to our history we can’t just pass the two item list; append will take it apart and put in the individual pieces. Instead we need to pass a list holding our two item list. append will take apart the outer list and leave the inner list alone.
(defun update-swarm-particle-2d (particle swarm fn x-bounds y-bounds)
(setf
(history particle)
(append
(history particle)
(list (list (x-coord particle) (y-coord particle))))))
But that’s very ugly and takes up a lot of room. Let’s hide it in a function:
(defun update-swarm-particle-2d (particle swarm fn x-bounds y-bounds)
(update-particle-history-2d particle))
(defun update-particle-history-2d (particle)
(setf
(history particle)
(append
(history particle)
(list (list (x-coord particle) (y-coord particle))))))
Is That Your Final Answer?
With that little bit of record keeping code out of the way we can move on to the most important part of this entire algorithm: Checking whether or not the particle has a good answer in it. That’s the whole reason we programmed this swarm in the first place. The whole purpose of a particle is to test out new answers to see if they are better than the answer we’re currently using.
I can’t stress this enough! This is where the magic happens!
But just because it is important doesn’t mean it is hard. In fact, checking for answers is downright easy:
(defun update-swarm-particle-2d (particle swarm fn x-bounds y-bounds)
(update-particle-history-2d particle)
(let ((particle-answer (funcall fn (x-coord particle) (y-coord particle))))
(when (< particle-answer (best-answer swarm))
(setf (best-answer swarm) particle-answer)
(setf (best-x swarm) (x-coord particle))
(setf (best-y swarm) (y-coord particle)))))
We use funcall to feed the particle’s current x and y coordinates into whatever function has been passed into our optimizer. We store the answer in the local “particle-answer” variable and then compare it to the swarm’s current best answer. If the particle-answer is better we update the swam with a new best answer and new best coordinates. Pretty straightforward even with all the parenthesis.
A Little More To The Left…
We’re now halfway through our five item checklist for updating a particle. The next step is to adjust the particle’s velocity to point it slightly more towards our current best answer. There are lots of ways to do this, but for this Let’s Program I’m going to keep things really simple. This might make our swarm intelligence a little dumber than some of the more elegant algorithms, but it will make it much easier to blog about. If you’re interested in better swarms you can always use my code as a simple starting point to teach you enough of the basics to research and build your own, better optimizer.
For our simple velocity update what we want to do is calculate a target velocity that will send us hurtling straight towards the current swarm best answer. Then we want to take some fraction of that target velocity and add it to some fraction of the particle’s current velocity. Maybe something like 30% of the target velocity plus 80% of the current velocity (The two percentages don’t have to add up to 100%. We’re taking two fractions of two different things, not slicing one big thing into two pieces).
Deciding on exactly how much of each velocity to use has a big impact on your swarm. Large amounts of target velocity will focus your particles like a laser on whatever answer seems good at the time. Put more weight on current velocity and particles will lazily drift about exploring more data for a while before finally meeting up in the general vicinity of a good answer.
This is the sort of code that can get messy fast, so let’s put it into a function to avoid cluttering up update-swarm-particle-2d. All this function really needs to function is a particle to update and a target coordinate to point the particle at.
(defun update-swarm-particle-2d (particle swarm fn x-bounds y-bounds)
(update-particle-history-2d particle)
(let ((particle-answer (funcall fn (x-coord particle) (y-coord particle))))
(when (< particle-answer (best-answer swarm))
(setf (best-answer swarm) particle-answer)
(setf (best-x swarm) (x-coord particle))
(setf (best-y swarm) (y-coord particle))))
(update-particle-velocity-2d particle (bext-x swarm) (best-y swarm)))
And now for the code itself:
(defun update-particle-velocity-2d (particle target-x target-y)
(let ((target-x-vel (- target-x (x-coord particle)))
(target-y-vel (- target-y (y-coord particle))))
(setf (x-vel particle) (+ (* 0.3 target-x-vel) (* 0.8 (x-vel particle))))
(setf (y-vel particle) (+ (* 0.3 target-y-vel) (* 0.8 (y-vel particle))))))
We figure out what the target x and y velocities should be by subtracting where we are from where we want to be, which will give us the speed we need to move at to hit our target in just one move. Example: The particle’s x position is five and the current best x is at two. Subtracting five from two gives us negative three (2-5=-3). So in order to reach the best x answer our particle needs to have a velocity of negative three units per update. Come up with a few more examples on your own if you’re having trouble following along.
Once we have target velocities it’s very easy to update the particle to a mix of 80% of it’s current velocity plus 30% of the best-answer seeking target velocity. Of course, it doesn’t have to be 80% and 30%. That’s just an example. We’ll probably have to run several tests to get a good feel for what values we should use. Let’s make that easier on ourselves by moving these magic numbers out of the code and into global variables.
(defparameter *original-velocity-weight-2d* 0.8)
(defparameter *target-velocity-weight-2d* 0.3)
(defun update-particle-velocity-2d (particle target-x target-y)
(let ((target-x-vel (- target-x (x-coord particle)))
(target-y-vel (- target-y (y-coord particle))))
(setf (x-vel particle)
(+ (* *target-velocity-weight-2d* target-x-vel)
(* *original-velocity-weight-2d* (x-vel particle))))
(setf (y-vel particle)
(+ (* *target-velocity-weight-2d* target-y-vel)
(* *original-velocity-weight-2d* (y-vel particle))))))
Much better.
But It Does Move!
Now that we’ve set the particle’s new velocity all that is left is to use that velocity to make the particle actually move. This is as simple as some basic addition and a couple quick checks to make sure the particles are in bounds.
(defun update-swarm-particle-2d (particle swarm fn x-bounds y-bounds)
(update-particle-history-2d particle)
(let ((particle-answer (funcall fn (x-coord particle) (y-coord particle))))
(when (< particle-answer (best-answer swarm))
(setf (best-answer swarm) particle-answer)
(setf (best-x swarm) (x-coord particle))
(setf (best-y swarm) (y-coord particle))))
(update-particle-velocity-2d particle (best-x swarm) (best-y swarm))
(let ((updated-x (+ (x-coord particle) (x-vel particle)))
(updated-y (+ (y-coord particle) (y-vel particle))))
(setf (x-coord particle) (max (first x-bounds) (min (second x-bounds) updated-x)))
(setf (y-coord particle) (max (first y-bounds) (min (second y-bounds) updated-y)))))
I’m using a pretty cool trick here for keeping a number inside of bounds. Normally you would use two if statements to check if the number was bigger than the upper boundary or smaller than the lower boundary. Instead I keep it inside the upper boundary by just asking for the min value between our upper boundary and our given value. If our value is bigger than the upper boundary it will get discarded by the min. Then I do the same thing for the lower boundary with the max value. It lets you do boundary math in a single line of nested functions instead of needing conditional logic.
Not really a huge time saver, but I’ve always thought it was a nifty little pattern.
I Sure Hope This Works
Supposedly our code can now set particle history, update the swarm, change velocity and then move the particle. Time to see whether or not any of this code actually works, or if I’ll need to rewrite most of this before posting!
[1]> (load “swarm.lisp”)
;; Loading file swarm.lisp …
;; Loaded file swarm.lisp
T
[2]> (defparameter *test-swarm* (generate-swarm-2d 1 -10 10 -10 10))
*TEST-SWARM*
[3]> (defparameter *test-particle* (first (particle-list *test-swarm*)))
*TEST-PARTICLE*
[4]> (print-swarm-2d *test-swarm*)
Best input:<0, 0>
Best answer:8.8080652584198167656L646456992
pos:<0.40933418, -5.2009716> vel:<-6.6420603, -5.447151>
NIL
[5]> (update-swarm-particle-2d *test-particle* *test-swarm* #’double-parabola ‘(-10 10) ‘(-10 10))
-9.558693
[6]> (print-swarm-2d *test-swarm*)
Best input:<0.40933418, -5.2009716>
Best answer:27.21766
pos:<-4.904314, -9.558693> vel:<-5.313648, -4.357721>
NIL
Looks good. We build a swarm with exactly one particle and update that particle. You can see that before the update the swarm’s best answer is our ridiculously huge default. After the update the swarm’s best input has changed to the original position of the particle. We can also see that the particle’s velocity has shifted and that it updated it’s position successfully.
One Small Step For A Particle, Next A Giant Leap For Our Swarm
There was some pretty heavy code in this update, but that was expected. Updating particles is the heart of our entire algorithm. Now that that’s working the next post should be a breeze. All we have to do is upgrade from updating one particle once to updating an entire swarm of particles constantly… or at least until we get a workable answer.
* You’re reading an AI programming blog, of course you own a graphing calculator.